


리트코드 - 208. Implement Trie (Prefix Tree)
문제 설명
트라이(Trie) 또는 접두어 트리(prefix tree)는 문자열 데이터 집합에서 키(key)를 효율적으로 저장하고 검색하는 데 사용되는 트리 구조의 데이터 구조입니다. 이 데이터 구조의 다양한 응용 사례가 있으며, 자동완성 및 맞춤법 검사기 등이 있습니다.
트라이 클래스를 구현하세요:
- Trie() : 트라이 객체를 초기화합니다.
- void insert(String word) : 문자열 word를 트라이에 삽입합니다.
- boolean search(String word) : 문자열 word가 트라이에 있는 경우(이전에 삽입된 경우) true를 반환하고, 그렇지 않으면 false를 반환합니다.
- boolean startsWith(String prefix) : 이전에 삽입된 문자열 중에서 접두사 prefix를 가지는 문자열이 있는 경우 true를 반환하고, 그렇지 않으면 false를 반환합니다.
의사코드
| class Node Map children boolean isEndOfWord 생성자 children = new HashMap isEndOfWord = false class Trie Node root 생성자 root = new Node insert 메소드(word) 현재Node = this.node 반복문 시작 (word의 각 문자 하나씩) if (현재Node의 children에 c가 없다면) 현재Node의 children에 새로운 Node를 추가 현재Node = 현재 Node의 children에서 c에 해당하는 Node로 갱신 반복문 종료 현재Node의 isEndOfWord를 true로 설정 search 메소드(word) searchNode(this.root, word) 메서드 호출하여 Node 반환 if (위의노드 = null) ? true 리턴 : false 리턴 searchNode 메소드(node, word) if (word 길이 == 0) if (Node의 isEndOfWord = true) ? Node : null c = word의 첫번째 문자열 자식Node = node의 children에서 c에 자식Node를 가져옴 if (childrenNode = null) null을 리턴 searchNode(childrenNode, word에서 앞글자 빼고 남은 값) 재귀적 호출 startsWith 메소드(prefix) 현재Node = this.root 반복문 시작 (prefix의 각 문자 하나씩) 자식Node = 현재Node의 children에서 c에 해당하는 자식Node를 가져옴 if (자식Node = null) false를 리턴 현재Node = 자식Node 반복문 종료 true 리턴 |
풀이코드
public class Node {
public Map<Character, Node> children;
public boolean isEndOfWord;
public Node() {
this.children = new HashMap<>();
this.isEndOfWord = false;
}
}
class Trie {
private Node root;
public Trie() {
this.root = new Node();
}
public void insert(String word) {
Node currentNode = this.root;
for (char c : word.toCharArray()) {
if (!currentNode.children.containsKey(c)) {
currentNode.children.put(c, new Node());
}
currentNode = currentNode.children.get(c);
}
currentNode.isEndOfWord = true;
}
public boolean search(String word) {
return searchNode(this.root, word) != null;
}
public Node searchNode(Node node, String word) {
if (word.length() == 0) {
if (node.isEndOfWord) {
return node;
} else {
return null;
}
}
char c = word.charAt(0);
Node childrenNode = node.children.get(c);
if (childrenNode == null) {
return null;
}
return searchNode(childrenNode, word.substring(1));
}
public boolean startsWith(String prefix) {
Node currentNode = this.root;
for (char c : prefix.toCharArray()) {
Node childNode = currentNode.children.get(c);
if (childNode == null) {
return false;
}
currentNode = childNode;
}
return true;
}
}코드설명
trie 알고리즘을 구현하는 문제이다.
trie 알고리즘은 트리의 일종으로 문자열의 키를 효율적으로 저장하고 검색하기 위한 자료구조이다.
접두사 검색, 자동 완성, 맨 앞부터 특정 문자로 시작하는 단어 검색등에 사용될 수 있다.
기본 노드 구성

기본적으로 node의 구성은 위와 같다.
node는 Map 형태의 children을 가지고있고 각 key값은 string값이다. 그리고 value로는 node 값을 가진다.
먼저 이것을 간단히 a라는 string을 추가한다고 표현해보자.

a라는 값을 추가하면 key에는 a값이 들어가고 새 노드를 가져야 한다.
동그라미는 노드가 있다는 것을 뜻하고, 안의 a는 key값을 의미한다.
이것을 확장해서 able 이라는 단어를 추가한다고 하면

이렇게 될 수 있겠다. 단어의 마지막에선 끝을 알려주는 isEndOfWord 값을 가져야 한다.
다시 정리하면 node는 Map형태의 children과 isEndOfWord를 가진다.
Trie 자료구조(알고리즘)
trie 구조에서 root노드는 아무런 값도 가지고 있지 않다.
따라서 trie 클래스를 생성자에서 root 노드를 먼저 생성해준다.
첫째로 insert 메소드를 해보자.
ac라는 단어를 추가한다고 하면 먼저 현재 노드를 루트노드로 맞춰준다.

다음으로 ac를 배열로 만들어서 반복 순회해준다.
먼저 a부터 확인하여, a를 key값으로 가지는지 확인한다.
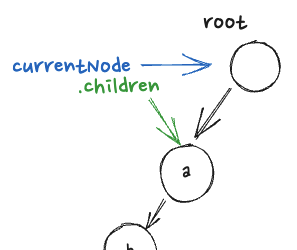
key값을 가지고 있고, node가 있으므로 not null이다.
다음으로 c를 확인하는데, c 노드의 key값이 없으므로 node 또한 없다. 그럼 만들어준다.

다 만들었으면, c가 문자열의 끝이라는 것을 추가해줘야 한다.

이렇게 해야하는 이유는 나중에 search 메소드나 startwith 메소드에서 사용하기 위함이다.
요구사항에는 없지만 자동완성 메소드에서도 활용이 가능하다.
둘째로 search 메소드다.
public boolean search(String word) {
return searchNode(this.root, word) != null;
}그냥 문자열을 잘라서 해도되는데 배운 내용 정리겸 재귀적으로 구현해봤다.
search메소드 내에선 파라미터(node, word)로 오버로딩된 search메소드를 호출한다.
이 오버로딩된 메소드에서 node값이 반환되면 true이고 false이다.
public Node searchNode(Node node, String word) {
if (word.length() == 0) {
if (node.isEndOfWord) {
return node;
} else {
return null;
}
}
char c = word.charAt(0);
Node childrenNode = node.children.get(c);
if (childrenNode == null) {
return null;
}
return searchNode(childrenNode, word.substring(1));
}오버로딩 된 search메소드를 다시 설명해보면...재귀적으로 구현되어 있다.
word의 크기가 0이면서 node가 끝문자열이라면 node를 반환하고, 만일 크기만 0이면 null을 반환한다.
(사실 크기가 0이면서 null인 경우는 insert가 잘못된 경우이긴 하다.)
이후에 word의 첫글자를 잘라서 이 key를 값으로 가지는 value(자식node)가 있는지 확인한다.
없다면, null을 반환한다.
다음 문자열을 찾기 위해서 word문자열 앞을 잘라버리고, 자식node와 word문자열을 다시 파라미터로 search메소드를 호출한다.
이렇게 하면 정확히 일치하는 문자열이 있으면 node가 반환되고 아니면 null이 반환된다.
1) b라는 단어를 찾는 예시
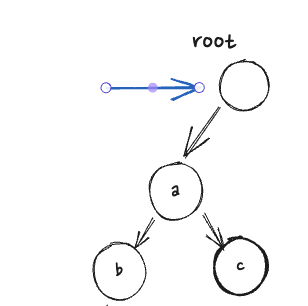
먼저 루트node와 문자열 "b"를 파라미터로 가지고, "b"의 크기를 확인하는데, "b"는 크기가 0이 아니다.

그래서 자식node를 찾아봤는데, b는 없기 때문에 null을 반환한다.
null을 반환하므로 search메소드에서는 false를 리턴한다.
2) ab를 찾는 예시
여기까지는 똑같다. root의 자식node중에 a가 있으니 a의 node와, "b" 문자열을 파라미터로 다시 search메소드를 부른다.
(ab에서 a를 잘라 b만 가짐)

이제 a의 자식node에서 b를 찾는데 b가 있으니 b의 node와 "" 문자열로 다시 search를 호출한다.
이 때, 문자열의 크기가 0이므로, b의 node가 isEndOfWord 를 확인하는데...false이다.
문자열이 끝난게 아니기 때문에 false를 리턴하고, 상위 search에서도 false를 리턴한다.
3) ac를 찾는 예시
2) 예시와 완전히 똑같고 a의 자식node에서 c를 찾는데 c가 있으니 c의 node와 "" 문자열로 다시 search를 호출한다.
이 때, 문자열의 크기가 0이므로, c node의 isEndOfWord 를 확인하는데...true이므로 c node를 반환한다.
node가 있으므로 true를 리턴한다.
셋째로 startsWith메소드다.
search와 원리는 비슷한데 간단하게 재귀대신 toCharArray로 반복문을 돌렸다.
search에서 마지막 isEndOfWord를 확인하냐 안하냐의 차이만 있을뿐 로직은 같다.
문자열을 잘라 노드를 순회하면서 자식node를 안가지면 false를 리턴하게 만들었다.
사실 이 메소드가 설명이 먼저 나왔으면 둘째번 메소드가 이해가 쉬웠을 것이다.
시간복잡도 - O(n) (n은 각 메소드별 파라미터로 주어지는 문자열의 길이)
공간복잡도 - O(m) (m은 trie의 깊이)
문제를 풀며 생각한 흐름과 배운 점
trie를 코드로 적용하려니 이게 코테에서 나오면 어디까지 적어야할까 고민이 많았다.
처음 보는 자료구조이니 재귀적방법과 일반 순회방법 두가지 방법을 모두 사용해보고자 코드를 작성했다.
이외에 개선한 점은...
여태까지 작성하던 의사코드를 조금 더 깔끔하게 적어보려 노력하였고,
팀원이 추천한 프로그램을 이용하여 가시적으로 설명을 추가하려 해 본 것이다.
그런데 문제 푸는 시간 제외하고
글 쓰는데만 네시간이 넘게 걸려서 공부하는 입장에서 정리에 이만큼 쓰는게 맞나 심하게 고민이 되기는 한다.
다른코드
class Trie {
Node root;
public Trie() {
root = new Node();
}
public void insert(String word) {
root.insert(word, 0);
}
public boolean search(String word) {
return root.search(word, 0);
}
public boolean startsWith(String prefix) {
return root.startsWith(prefix, 0);
}
class Node {
Node[] nodes;
boolean isEnd;
Node() {
nodes = new Node[26];
}
private void insert(String word, int idx) {
if (idx >= word.length()) return;
int i = word.charAt(idx) - 'a';
if (nodes[i] == null) {
nodes[i] = new Node();
}
if (idx == word.length()-1) nodes[i].isEnd = true;
nodes[i].insert(word, idx+1);
}
private boolean search(String word, int idx) {
if (idx >= word.length()) return false;
Node node = nodes[word.charAt(idx) - 'a'];
if (node == null) return false;
if (idx == word.length() - 1 && node.isEnd) return true;
return node.search(word, idx+1);
}
private boolean startsWith(String prefix, int idx) {
if (idx >= prefix.length()) return false;
Node node = nodes[prefix.charAt(idx) - 'a'];
if (node == null) return false;
if (idx == prefix.length() - 1) return true;
return node.startsWith(prefix, idx+1);
}
}
}각각의 메소드들은 가볍게 작성되어 있다. 하지만 내가 생각하기엔 문제가 있다.
첫번째로 각각 자식노드가 26개의 배열을 차지하는 것은 불필요한 메모리 공간이라고 생각한다.
-> (9/11수정)
배열은 크기를 설정하면 참조값이 연속적으로 쓰여지는 것이고 객체가 할당된 것이 아니기 때문에 메모리 공간을 차지하지 않는다.
두번째로 node가 메소드를 가지고 있는데.. 이 기능들은 trie의 기능이지 node의 기능이 아니다.
메소드 분리가 잘못된 것 같다.
또다른 생각
간단하게 구현된 코드를 보니 내코드가 불필요하게 길다는 느낌도 든다.
코테에서 필요한 것은 시간내에 문제를 해결하는 능력이 가장 중요하다고 하니, 모두 익혀두어야겠다.
아빠가 좋아 엄마가 좋아에선 둘다 좋아하는게 좋은 것처럼.
정리
trie에 대한 기본 개념 공부
'CS > 코딩테스트' 카테고리의 다른 글
| 리트코드 - 212. Word Search II (0) | 2023.09.12 |
|---|---|
| 리트코드 - 211. Design Add and Search Words Data Structure (0) | 2023.09.10 |
| 리트코드 - 230. Kth Smallest Element in a BST (0) | 2023.09.08 |
| 리트코드 - 530. Minimum Absolute Difference in BST (0) | 2023.09.06 |
| 리트코드 - 162. Find Peak Element (0) | 2023.09.04 |
남에게 설명할 때 비로소 자신의 지식이 된다.
포스팅이 도움되셨다면 하트❤️ 또는 구독👍🏻 부탁드립니다!! 잘못된 정보가 있다면 댓글로 알려주세요.



