


리트코드 - 133. Clone Graph
출처 - https://leetcode.com/problems/clone-graph/?envType=study-plan-v2&envId=top-interview-150
문제 설명
연결된 무방향 그래프의 노드에 대한 참조가 주어집니다.
해당 그래프의 깊은 복사본(클론)을 반환하세요.
그래프의 각 노드는 값을 가지고 있으며 (int)와 해당 노드의 이웃 노드 목록(List[Node])으로 구성되어 있습니다.
class Node {
public int val;
public List<Node> neighbors;
}테스트 케이스 형식
간단하게, 각 노드의 값은 노드의 색인과 동일합니다.(1부터 시작합니다)
예를 들어, 값이 1인 첫 번째 노드, 값이 2인 두 번째 노드 등입니다. 그래프는 인접 리스트를 사용하여 표시됩니다.
인접 리스트는 유한 그래프를 나타내는 데 사용되는 정렬되지 않은 목록의 모음입니다. 각 목록은 그래프의 노드의 이웃 노드 집합을 설명합니다.
주어진 노드는 항상 값이 1인 첫 번째 노드일 것입니다. 주어진 노드의 복사본을 반환해야 하며, 복제된 그래프에 대한 참조로서 반환되어야 합니다.
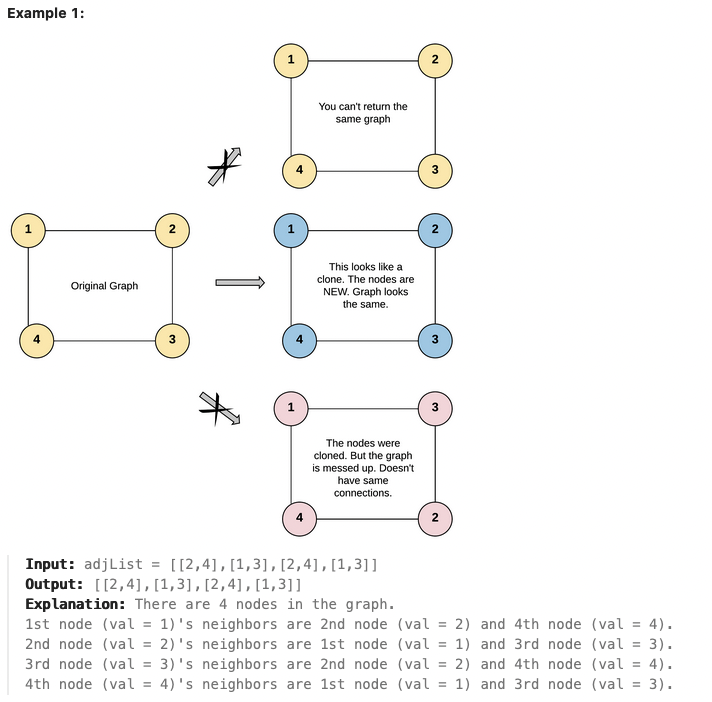
의사코드
| 함수 cloneGraph (node) if (node = null) null 리턴 nodePair = new HashMap queue = new LinkedList queue에 node를 offer newNode = new Node(node.val) nodePair에 key=node, value=newNode 반복문 시작 (queue가 비어있지 않으면) originNode = queue에서 poll 반복문 시작 (originNode의 이웃Node 순회) if (nodePair가 key값으로 이웃Node를 가지지 않으면) copyNode = new Node(이웃Node의 val) nodePair에 key = 이웃Node, value = copyNode 삽입 queue에 이웃Node를 offer nodePair의 key가 originNode인 value(Node)를 가져오고, 이 Node에 nodePair의 key가 이웃Node인 value(copyNode) 추가 반복문 종료 newNode 리턴 |
풀이코드
1번 방식
class Solution {
public Node cloneGraph(Node node) {
if (node == null) {
return null;
}
Map<Node, Node> nodePair = new HashMap<>();
Queue<Node> queue = new LinkedList<>();
queue.offer(node);
Node newNode = new Node(node.val);
nodePair.put(node, newNode);
while (!queue.isEmpty()) {
Node originNode = queue.poll();
for (Node n : originNode.neighbors) {
if (!nodePair.containsKey(n)) {
Node copyNode = new Node(n.val);
nodePair.put(n, copyNode);
queue.offer(n);
}
nodePair.get(originNode).neighbors.add(nodePair.get(n));
}
}
return newNode;
}
}2번 방식
class Solution {
private Map<Node, Node> nodePair = new HashMap<>();
public Node cloneGraph(Node node) {
if (node == null) {
return null;
}
if (nodePair.containsKey(node)) {
return nodePair.get(node);
}
Node newNode = new Node(node.val);
nodePair.put(node, newNode);
for (Node n : node.neighbors) {
newNode.neighbors.add(cloneGraph(n));
}
return newNode;
}
}코드설명
깊은 복사로 문제이다.
기본적으로 1,2번 모두 Map을 이용하여 key값에 원본Node값, value값에 복사Node를 넣는 방식을 사용했다.
1번 방식은 Queue를 활용한 BFS 방식이고, 2번 방식은 재귀를 사용한 DFS 방식이다.
1번 방식
너비 우선 탐색(BFS)을 활용하여 각 Node를 확인하여, 이웃Node를 탐색해나가는 과정이다.
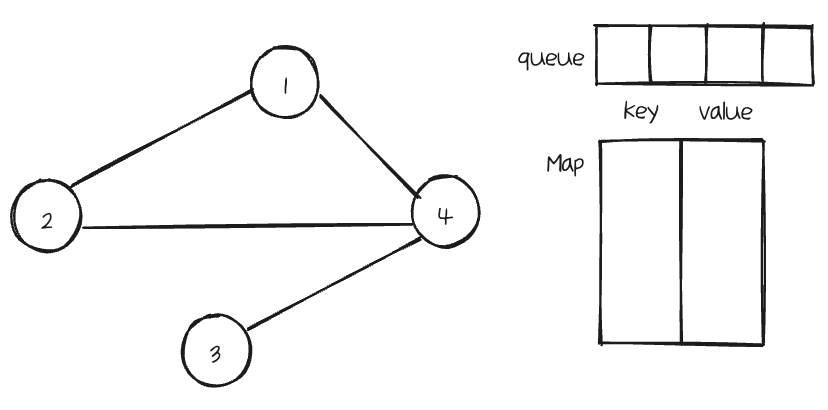
예를 들어 위와 같은 무방향 그래프가 있다고 하면,

먼저 파라미터로 받은 Node의 val값을 복사하여 새 Node를 만든다.
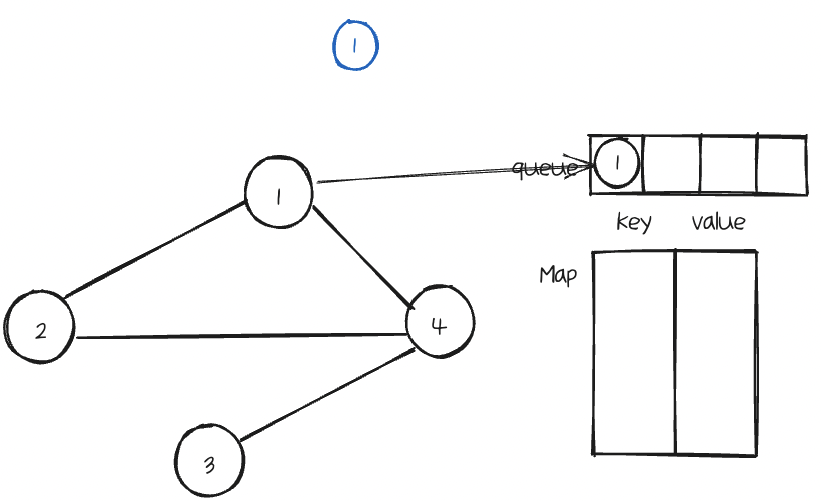
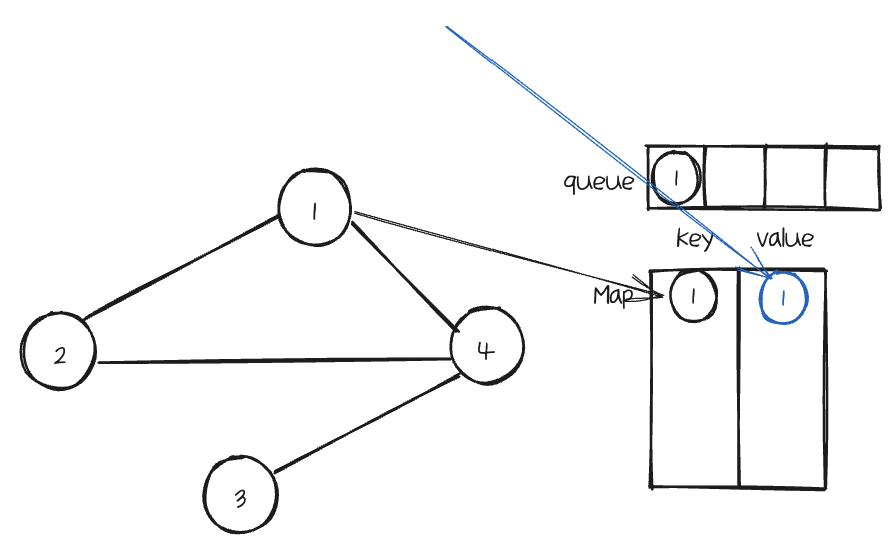
다음으로 Node를 queue에 offer하여 넣은 다음 map에 key는 Node로, value로는 새Node를 넣는다.
그리고 반복문을 시작한다.
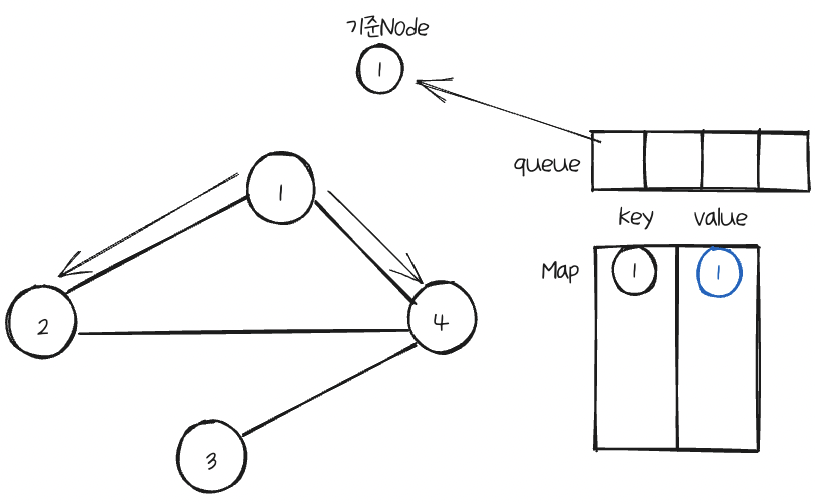
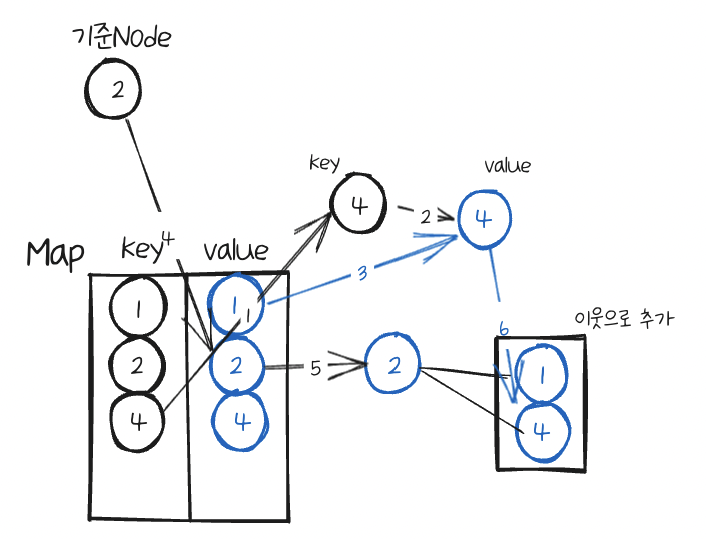
만일 queue가 비어있지 않으면 꺼낸다음, 이것을 기준Node로 삼는다.
기준Node의 이웃Node를 확인한다.
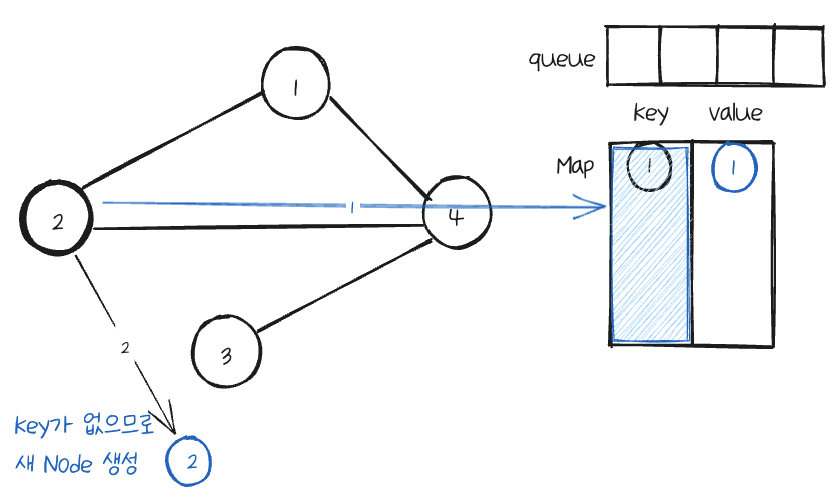
먼저 이웃Node인 2를 확인하는데 map에 key값을 확인하여 없으면 똑같이 새Node를 만든다음, 이 쌍을 map에 넣는다.
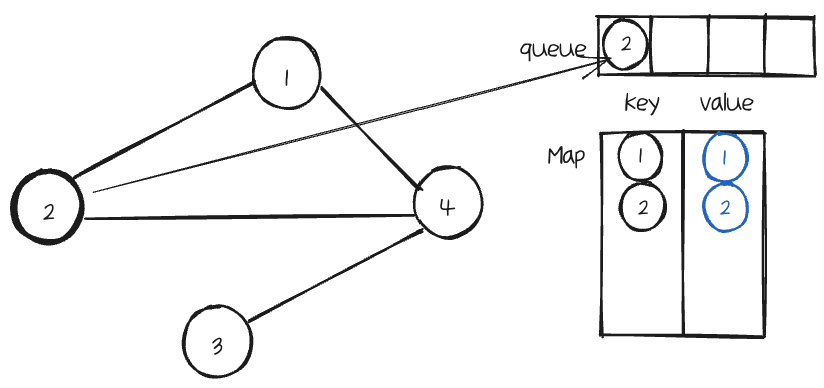
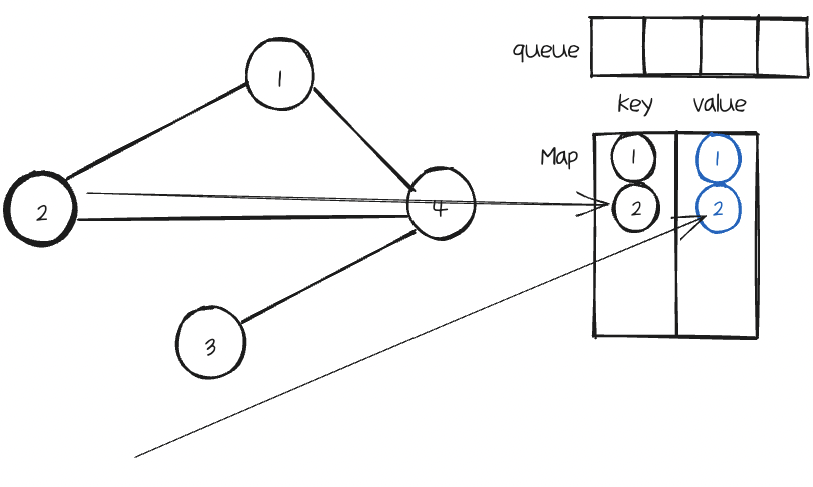
그리고 queue에도 이 Node값을 넣는다.
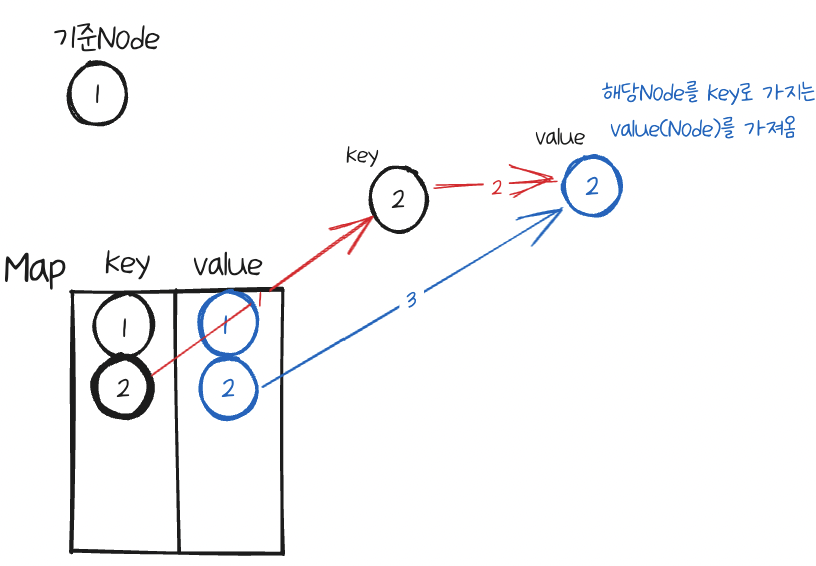
다음으로 Map에서 이 이웃Node를 Key로 가지는 value를 가져온다.

기준Node의 value(Node)를 가져와서 이웃으로 추가해준다.
이렇게 하는 이유는 깊은 복사를 위해서 새롭게 만든 Node를 연결 시켜주어야 하기 때문이다.
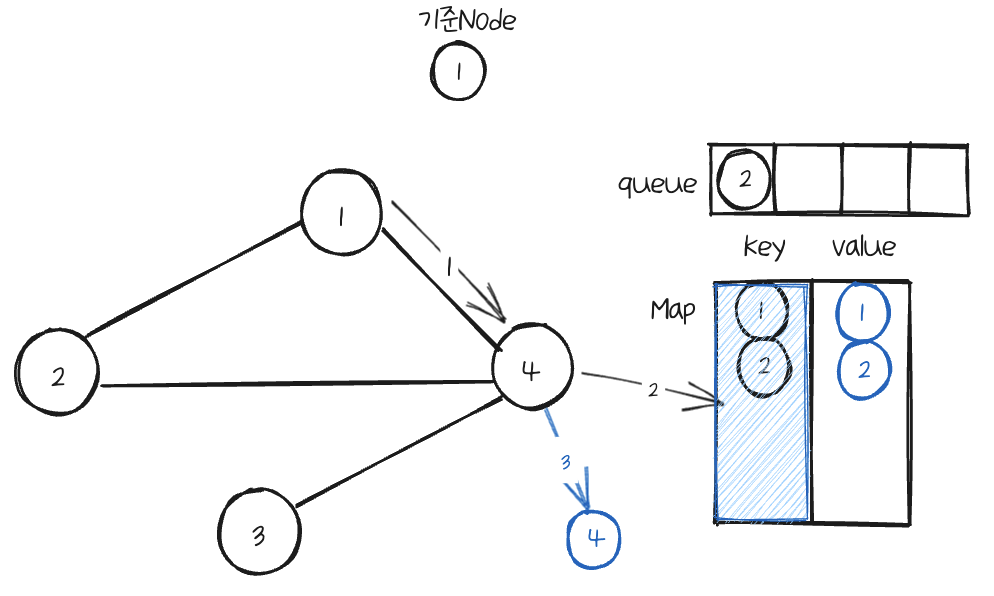

다음 이웃 Node인 4를 확인한다. 마찬가지로 Map을 확인하여 넣어준다.
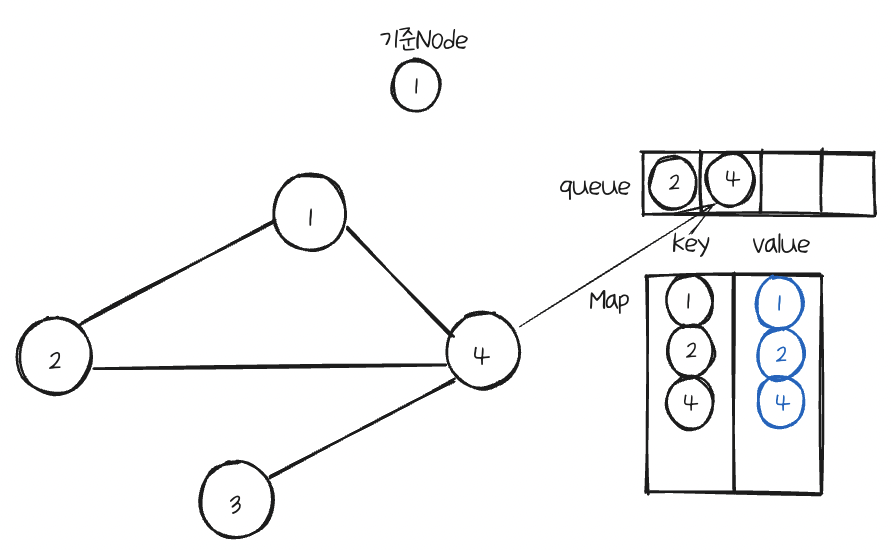
queue에도 추가해준다.
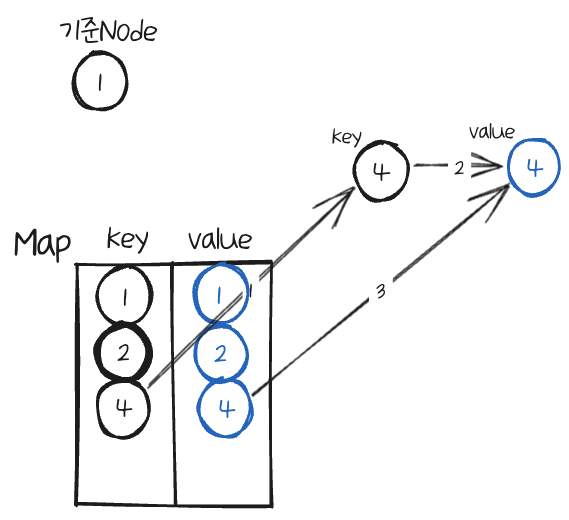

그리고 이 이웃Node의 value(Node)를 가져와서 기준Node에 이웃에 똑같이 추가해준다.
첫번째 반복문이 끝났다.
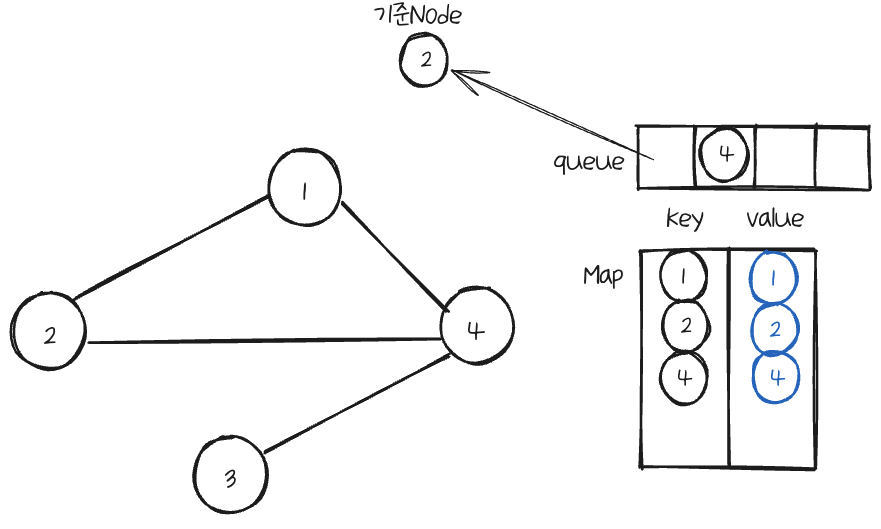
다시 Queue를 확인해서 비어있지 않으면, FIFO에 의해 첫번째 값을 꺼내 기준Node로 한다.
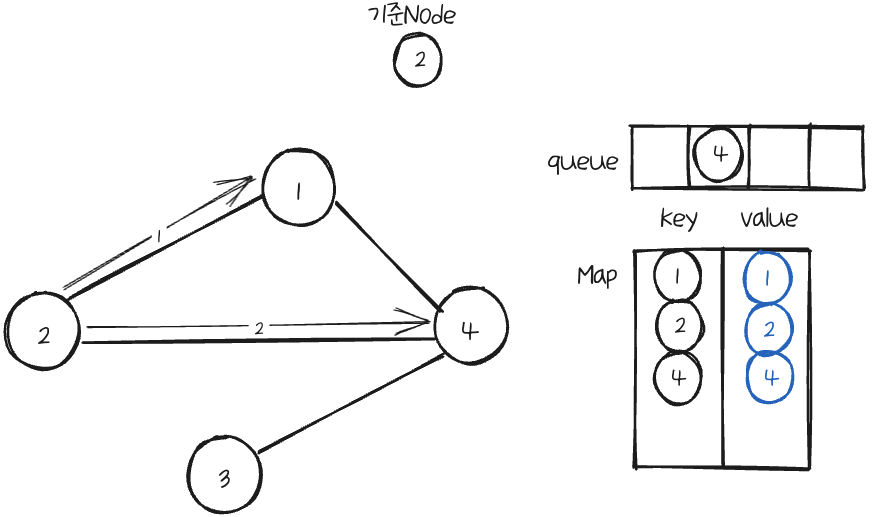
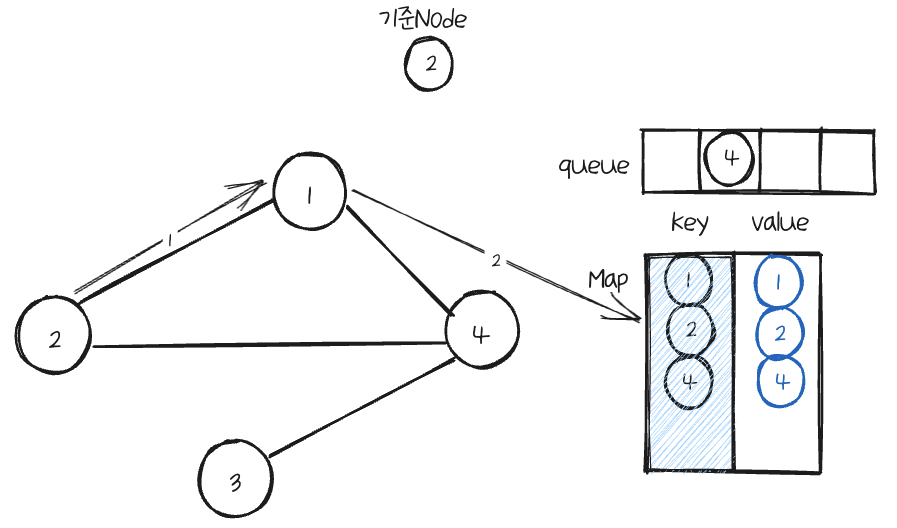
기준Node의 이웃Node를 순차적으로 다시 탐색하는데, 1 Node부터 확인했더니 Map에 key로 가지고 있다.
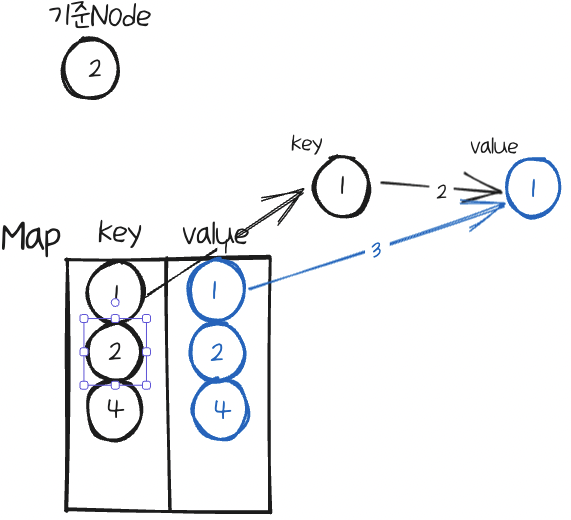

그럼 이 Node의 value를 가져와서, 마찬가지로 기준Node의 이웃으로 추가해준다.
마찬가지로 4도 이미 key로 있으므로 추가해준다.
두번째 반복문이 끝났다.

queue가 비어있지 않으므로 Node를 꺼내고, 기준Node로 하여 똑같이 반복해주면 된다.
1과 3을 확인할 것이고, 1은 map에 있으므로 이웃만 추가, 3은 없으므로 map에 추가하고 새Node 4의 이웃 추가를 할 것이다.
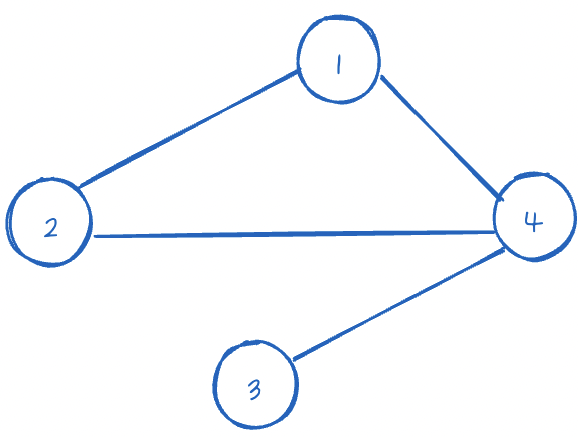
결과적으로 똑같은 Node가 생성이 된다.
2번 방식
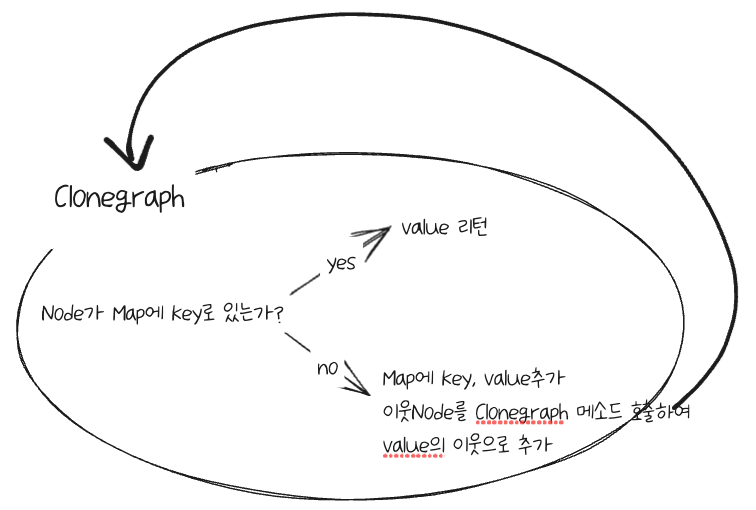
queue를 쓰는 대신 함수를 재귀적으로 호출하여 DFS 방식으로 구현했다.
먼저 Node가 null일 때는 null을 리턴한다.
만일 Node가 이미 map key값으로 있으면 value를 리턴하고, 없으면 새Node를 만들어 map에 value로 추가한다.
그리고 이Node의 이웃Node를 확인하여 clonegraph 메소드를 호출한다.
이웃이 있으면 계속 파고 들어가는 구조이므로 DFS방식이 된다.
시간복잡도 - O(v+e) (v는 정점(vertex)의 수, e는 간선(edge)의 수)
공간복잡도 - O(v) (map의 크기)
문제를 풀며 생각한 흐름과 배운 점
수업에서 배운 그래프 순회를 공부하면서 DFS에 꽂히다보니, Set으로 문제를 풀려고 했었다.
그렇게 한참을 풀다보니 Set으로 사용한 visited가 오히려 불필요하다는 생각이 들어, 바로 폐기해버렸다.
BFS도 적용해볼 겸 처음에는 queue를 써서 사용해보고, 다음으로 다시 DFS에 도전해서 재귀적으로 구현했다.
맨앞 언더바가 있는 변수
문제 예시에 파라미터에 _언더바가 있기에 궁금해서 찾아보니 이것은 이전에 사용하던 방식이라고 한다.
ide가 발달하기 전 private 변수나 하위 function을 표현할 때 사용하는 일종의 코딩컨벤션인 것이다.
요즘은 ide에서 잘 볼 수 있으므로 사용하지 않는 것 같다.
다른 코드
class Node:
def __init__(self, val = 0, neighbors = None):
self.val = val
self.neighbors = neighbors if neighbors is not None else []
class Solution:
def cloneGraph(self, node: 'Node') -> 'Node':
oldToNew={}
def dfs(node):
if node in oldToNew:
return oldToNew[node]
copy=Node(node.val)
oldToNew[node]=copy
for nei in node.neighbors:
copy.neighbors.append(dfs(nei))
return copy
return dfs(node) if node else None대체로 자바 코드는 다른 사람과 비슷했는데... 지나가다 파이썬 코드를 봤는데 너무 간단해서 약간 허탈했다.
왜 코테에서 파이썬으로 연습하라는 지 알 것 같다.
근데 자바로도 하다보면 재밌다..
글쓰기 시간 줄이기
오늘은 별거 없는(?) 데 글쓰는데 6시간이나 걸렸다.
처음에 테스트케이스를 통과한 코드가 뭔가 잘못 되어있어서 한참 그림그리면서 포스팅 하다 다 지우고 다시 했다.
노드는 그림으로 표현하는게 제일 쉬운데, 제일 귀찮은 작업같다.
글로만으로도 이해가 쉽게 표현하는 방법은 없을까 고민해봐야겠다.
또한 코테 시간 내에 BFS와 DFS를 빨리 구현해 낼 수 있어야 할 것 같다.
정리
그래프를 순회하는 두가지 방법(BFS, DFS)
'CS > 코딩테스트' 카테고리의 다른 글
| 리트코드 - 13. Roman to Integer (0) | 2023.09.17 |
|---|---|
| 리트코드 - 909. Snakes and Ladders (0) | 2023.09.15 |
| 리트코드 - 215. Kth Largest Element in an Array (0) | 2023.09.12 |
| 리트코드 - 212. Word Search II (0) | 2023.09.12 |
| 리트코드 - 211. Design Add and Search Words Data Structure (0) | 2023.09.10 |
남에게 설명할 때 비로소 자신의 지식이 된다.
포스팅이 도움되셨다면 하트❤️ 또는 구독👍🏻 부탁드립니다!! 잘못된 정보가 있다면 댓글로 알려주세요.



